A deep dive into DeepSeek-R1

Hello, in this post, we’ll take a closer look at the technical documentation of DeepSeek-R1, a reasoning model recently released by DeepSeek, and explore what kind of model DeepSeek-R1 really is.
DeepSeek, a Chinese company, has recently emerged as a strong player in the LLM space with the release of its cost-effective and high-performing DeepSeek-V3 model. On January 20, 2025, DeepSeek once again captured attention by releasing DeepSeek-R1, an open-source reasoning model. According to their internal benchmarks, DeepSeek-R1 demonstrates performance on par with or even surpassing OpenAI-o1. Notably, DeepSeek has also shared relatively detailed documentation on the model development process, which is expected to provide significant inspiration for open-source LLM research. It’s ironic that DeepSeek seems to embody "Open AI" more than OpenAI itself. 😅 Now, let’s dive into the technical report of DeepSeek-R1.
Summary
- DeepSeek has open-sourced two types of reasoning models: DeepSeek-R1-Zero and DeepSeek-R1. Both models are based on the DeepSeek-V3-Base model and have undergone additional training specifically for reasoning tasks.
- DeepSeek-R1-Zero was trained exclusively using large-scale reinforcement learning (RL) without any supervised fine-tuning (SFT). Despite this, it demonstrates impressive reasoning capabilities. However, it has some drawbacks, such as lower readability in outputs and mixed-language generation.
- To address these issues, DeepSeek refined the model using curated cold-start data and applied multi-stage training, resulting in the DeepSeek-R1 model. DeepSeek-R1 shows performance on par with OpenAI-o1-1217 in reasoning tasks.
- In addition to these two models, DeepSeek has also released 6 distilled models (1.5B, 7B, 8B, 14B, 32B, and 70B) based on DeepSeek-R1. These distilled models were trained on Qwen and Llama architectures.
Introduction
In the latest trends of LLM development, post-training has emerged as a factor just as important as pre-training. With a well-trained pre-trained LLM, the way subsequent training is conducted can enhance reasoning performance, create models aligned with societal values, or even develop personalized models. Since these tasks can be performed at a much lower cost compared to pre-training, there is a growing trend of research focused on post-training.
When it comes to reasoning performance, OpenAI's o1 series models have shown strong results in tasks like math, science problem-solving, and coding by explicitly increasing the length of the chain-of-thought process during inference. However, like other OpenAI models, the details of o1's training process remain largely undisclosed. According to OpenAI's official documentation, large-scale reinforcement learning (RL) was used in o1's training, and it was described as "data-efficient." This suggests that the model could be trained even without well-labeled chain-of-thought data, which is an intriguing hint.
While it's unclear whether DeepSeek-R1 drew direct inspiration from this, it similarly aims to achieve reasoning capabilities purely through RL-based training. Much like how AlphaZero mastered the game of Go without relying on human-created game records, DeepSeek-R1 explores whether a model can learn to reason within an RL framework without relying on reasoning-related labels (such as chain-of-thought annotations). This approach seeks to determine if the model can autonomously develop reasoning skills through self-improvement and interaction.
DeepSeek-R1-Zero
To explore whether reasoning can be learned using reinforcement learning (RL), DeepSeek-R1-Zero was trained without relying on supervised fine-tuning (SFT). Instead, it was trained exclusively using RL to explore chain-of-thought (CoT) paths. This approach allows the model to autonomously discover and refine reasoning strategies without the need for labeled CoT data, demonstrating the potential of RL in developing reasoning capabilities in LLMs.
RL Algorithm
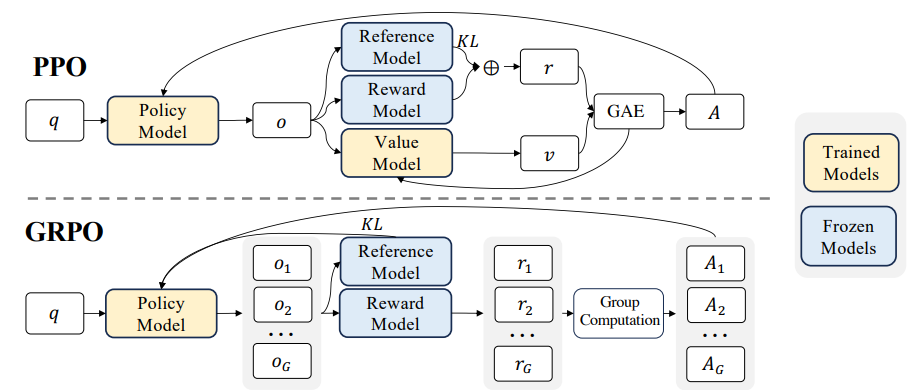
DeepSeek-R1-Zero utilizes Group Relative Policy Optimization (GRPO) for RL training. This method, proposed in the DeepSeekMath paper, differs from the commonly used Proximal Policy Optimization (PPO) in LLM fine-tuning. Unlike PPO, GRPO does not require a separate value model. Instead, it uses the average reward of multiple sampled outputs for the same input as a baseline, enabling more efficient training. For more detailed information, please refer to the DeepSeekMath paper!
Reward definition
Defining a reward metric to evaluate the model's outputs is essential for RL training. In DeepSeek-R1-Zero, a very simple rule-based reward definition is used, as outlined below:
- Accuracy Reward: Similar to how a reward is given for winning in a game of Go, a reward is provided when the model's reasoning output is correct. This encourages the model to generate accurate results.
- Format Reward: During training, the model is instructed to place its reasoning process between
<think>and</think>tags (see below). A reward is given based on whether the model adheres to this output format, ensuring proper structure in its responses.
Template for training prompt

prompt section is where the reasoning question for training is inserted.To ensure that the model does not rely on hints from the input prompt to construct its reasoning path and instead learns reasoning purely within the RL framework, DeepSeek-R1-Zero uses a fixed-format prompt template shown above during training.
Performance improvement over training
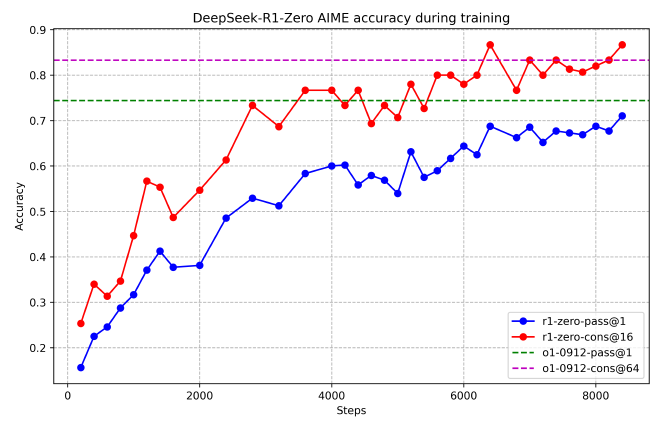
As the training progresses, a significant improvement in performance on reasoning tasks can be observed. The pass@1 score (the rate of correct answers on the first attempt) on the AIME 2024 benchmark jumped from 15.6% to 71.0%. This is comparable to the performance of OpenAI-o1-0912, demonstrating that RL training is working effectively.
Additionally, the performance can be further improved by using a majority voting strategy. This involves attempting the task 16 times and selecting the most frequently provided answer as the final answer. This can be seen as a form of ensemble learning. In this case, DeepSeek-R1-Zero's performance improves from 71.0% to 86.7%, surpassing the performance of OpenAI-o1-0912.
"Self-evolution" of the thought process
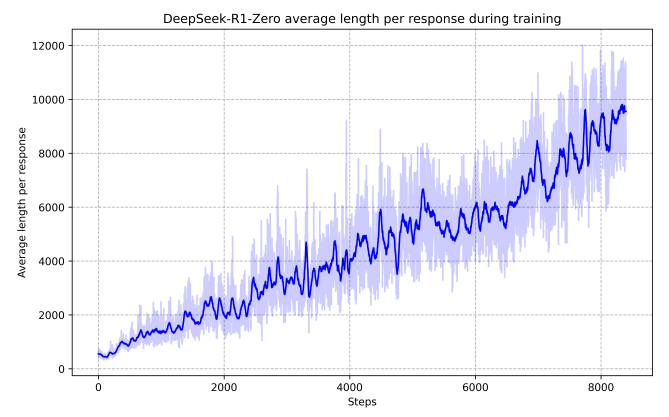
Next, we examined how the model's reasoning evolves during the training process. Interestingly, as training progresses, the model's chain-of-thought (CoT) process consistently increases. This means the model is learning that it needs to go through longer reasoning steps to arrive at the correct answer! Considering that this learning process occurred within an RL framework—where only the problem and answer were provided, and the model was allowed to freely develop its reasoning—rather than through supervised fine-tuning with labeled "thought processes," this is a remarkable result.
Looking deeper into the model's reasoning process reveals even more surprises. As more test-time computation is allowed, behaviors such as reviewing previous reasoning steps (reflection) begin to emerge. The fact that the model can learn such thought patterns without any explicit guidance is incredibly fascinating.
Aha-moment

As a striking example of the evolution of the reasoning process, it was observed that the model experiences an "aha-moment" during its thought process, where it seems to suddenly realize something. Around this time, the model spends a significant amount of time reviewing its initial solutions.
The authors, seemingly fond of this "aha-moment," share their sentiments in a somewhat reflective tone, expressing their fascination with this phenomenon.
This moment is not only an “aha moment” for the model but also for the researchers observing its behavior. It underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies. The “aha moment” serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems, paving the way for more autonomous and adaptive models in the future.
Limitations of DeepSeek-R1-Zero
While the effectiveness of the RL framework for reasoning training has been clearly demonstrated, DeepSeek-R1-Zero has the following drawbacks in practical use:
- Low readability
- Mixed-language outputs
DeepSeek-R1
Given the promising results of DeepSeek-R1-Zero, the following considerations arise:
- Cold-start data: DeepSeek-R1-Zero did not use cold-start data to guide or accelerate the overall training process. Could using high-quality, small-scale cold-start data improve performance or speed up convergence?
- Service perspective: While reasoning performance is crucial, equally important is how transparently the results are presented to users. Can a model be developed that not only performs well but also effectively constructs and displays chain-of-thought paths or demonstrates strong general capabilities?
Cold-start Data
Unlike DeepSeek-R1-Zero, DeepSeek-R1 uses a small amount of long-CoT data in the very early stages of training. While DeepSeek-R1-Zero required the model to undergo trial and error, leading to unstable initial learning, DeepSeek-R1 leverages long-CoT data as a form of "good policy demonstration" to stabilize fine-tuning.
The cold-start data was generated using the following methods:
- Outputs from few-shot prompting with long-CoT examples
- Outputs using prompts that enforce reflection and verification
- Outputs from DeepSeek-R1-Zero
- Results directly modified by human annotators
Advantages of Using Cold-start Data
- Readability: DeepSeek-R1-Zero's outputs often mix multiple languages and lack markdown formatting, making them less user-friendly. In contrast, DeepSeek-R1's cold-start data is carefully curated, ensuring that all responses include a summary of the reasoning process at the end, structured as follows:
|special_token| <reasoning_process> |special_token| <summary> - Performance Potential: By mimicking human reasoning processes in the cold-start data, DeepSeek-R1 achieved better performance compared to DeepSeek-R1-Zero.
Reasoning-oriented Reinforcement Learning
After completing the fine-tuning with cold-start data, the RL training process, similar to that of DeepSeek-R1-Zero, is conducted. During this phase, data requiring complex reasoning—such as coding, mathematics, science, and logical reasoning—are primarily used.
Although cold-start data was utilized, the issue of mixed languages in the chain-of-thought (CoT) outputs occasionally persisted. To mitigate this, a "language consistency" reward was introduced, which calculates the proportion of the target language in the CoT. While this led to a slight performance drop, it was a necessary step from a service perspective.
Generating SFT Training Data via Rejection Sampling
Once the reasoning-oriented RL phase concludes, data for the next round of training—Supervised Fine-Tuning (SFT)—is generated using the current model parameters. High-quality (CoT, answer) pairs are required for SFT, and a rejection sampling strategy is employed to achieve this. In simple terms, the model generates (CoT, answer) pairs, and low-quality data is filtered out through the following methods:
- Generative Reward Model: Unlike the previous rule-based rewards, here DeepSeek-V3 is used to score data by providing it with (CoT, predicted answer, correct answer) triplets.
- CoT Filtering: Outputs with mixed languages, overly long paragraphs, or code blocks are removed. (Interestingly, code blocks are sometimes included in CoT.)
- Answer Filtering: Multiple (CoT, answer) pairs are generated per prompt, and only those with correct answers are retained.
This process resulted in a total of 600,000 reasoning-related SFT training samples.
Non-Reasoning Data
DeepSeek-R1 was also trained to be versatile beyond reasoning tasks. To achieve this, the data processing pipeline used for DeepSeek-V3 training and a portion of the DeepSeek-V3 SFT data were utilized, creating a total of 200,000 non-reasoning samples.
Combining these, a total of 800,000 samples were used for 2 epochs of SFT training.
Second RL Training with Human Preference (Safety RL)
To further enhance reasoning capabilities and ensure the model's helpfulness and harmlessness, a final Safety RL training phase was conducted. For reasoning tasks, the same rule-based rewards from DeepSeek-R1-Zero were used, while for general tasks, rewards were aligned with human preferences.
Distillation
Finally, let’s explore how the reasoning performance of much smaller models like Qwen and Llama can be improved through the distillation of DeepSeek-R1.
Recall the 800,000 SFT datasets used in DeepSeek-R1's SFT phase? These were also used for distillation. The base models for distillation included:
- Qwen2.5-Math-1.5B
- Qwen2.5-Math-7B
- Qwen2.5-14B
- Qwen2.5-32B
- Llama-3.1-8B
- Llama-3.3-70B-Instruct
Notably, only SFT was used during distillation, without RL, as the goal was to evaluate the effectiveness of distilling reasoning capabilities learned through RL.
Benchmark
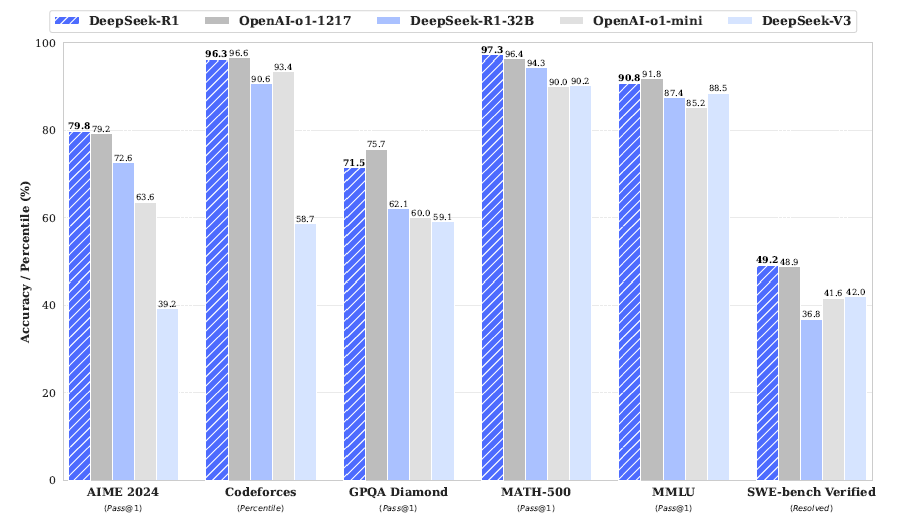
DeepSeek-R1 benchmark results
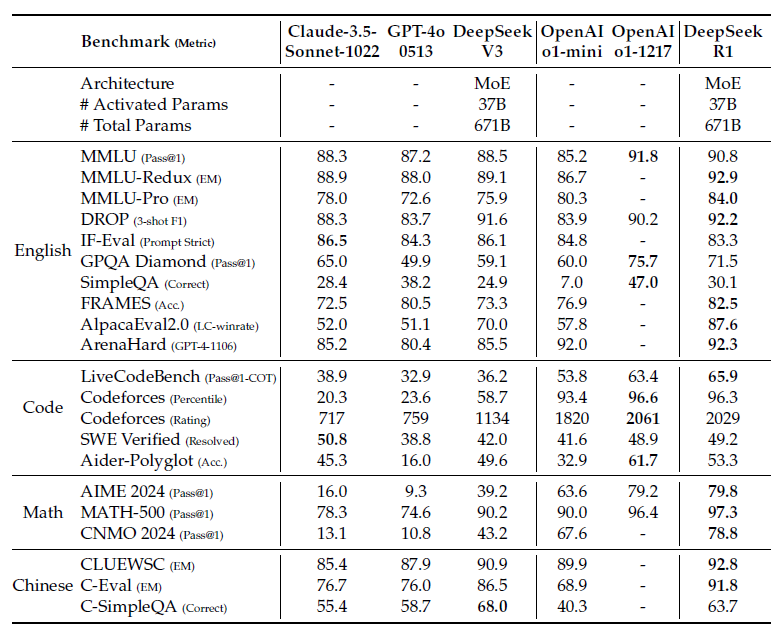
Here’s a brief summary of the DeepSeek-R1 model's performance benchmarks:
- Knowledge Benchmarks: Outperformed DeepSeek-V3 on benchmarks like MMLU, MMLU-PRo, and GPQA Diamond, demonstrating superior knowledge comprehension and reasoning.
- Long-Context-Dependent QA: Achieved excellent performance on the FRAMES benchmark, indicating strong ability to read documents and connect distantly related pieces of information.
- Factuality Benchmarks: Surpassed DeepSeek-V3 on SimpleQA, suggesting fewer hallucinations and better alignment between queries and learned knowledge. However, underperformed on the Chinese SimpleQA benchmark, likely due to the Safety RL training causing the model to reject certain queries. Without Safety RL, performance exceeds 70%.
- Instruction Following: Showed strong performance on IF-Eval, which evaluates how well the model follows format instructions. However, the reported score is lower than DeepSeek-V3, possibly due to a reporting error.
- Mathematical Problem Solving: Matched the performance of OpenAI-o1-1217 on math problem-solving tasks.
- Coding Benchmarks: Performed similarly to OpenAI-o1-1217 on coding benchmarks.
- Software Engineering Benchmarks: Slightly underperformed compared to OpenAI-o1-1217 on Aider-Polyglot but showed comparable performance on SWE verified.
These results highlight DeepSeek-R1's strengths in reasoning, knowledge comprehension, and instruction following, while also revealing areas for improvement, particularly in handling specific queries under safety constraints.
Distilled model benchmark
How did the 6 distilled models perform? Did they effectively inherit the capabilities of DeepSeek-R1 and excel at solving reasoning tasks?
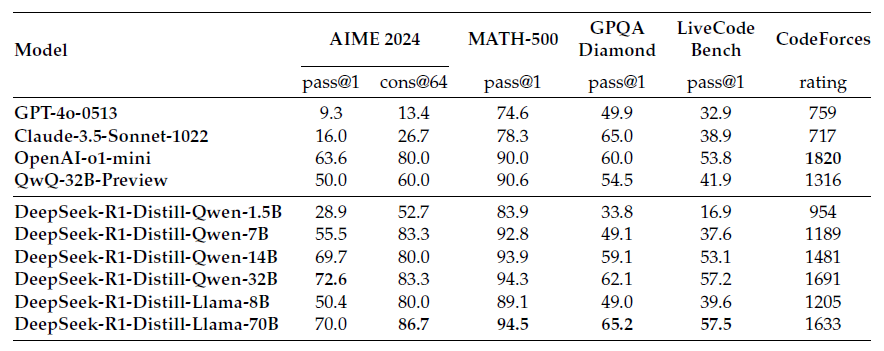
- DeepSeek-R1-Distill-Qwen-7B, distilled solely from DeepSeek-R1's outputs, even surpasses GPT-4o-0513. This clearly demonstrates the stark difference between reasoning and non-reasoning models.
- DeepSeek-R1-Distill-Qwen-14B outperforms QwQ-32B-Preview.
- DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Llama-70B surpass o1-mini.
- It is reported that additional RL training on these distilled models can further improve performance! (No results shown yet.)
Distillation vs RL
The power of the 800,000 reasoning training datasets created by DeepSeek-R1 is evident. So, which approach is better for reasoning training: using these 800k datasets for SFT or performing RL like DeepSeek-R1-Zero?

The above results compare the performance of DeepSeek-R1-Zero-Qwen-32B (a Qwen-32B model trained with RL) and DeepSeek-R1-Distill-Qwen-32B (a Qwen-32B model distilled using reasoning data generated by DeepSeek-R1). While RL training can achieve reasoning performance similar to QwQ-32B-Preview, it is less effective compared to distillation.
From this, we can draw the following two conclusions:
- Distilling a large model into a smaller one is highly effective and can even push performance beyond what can be achieved by large-scale RL training on smaller models.
- Conversely, while distillation is an economical and effective training strategy, the training of the large model required for distillation is ultimately indispensable.
Conclusion
Today, we explored the DeepSeek-R1 technical documentation to understand how reasoning capabilities can be imparted to LLMs. We observed that with simple RL rewards and effective training strategies, models can gradually learn "how to think." Personally, I found the fact that the chain-of-thought (CoT) process manifests in multiple languages (and even code!) to be a positive aspect. While it may seem like a drawback due to the lack of language constraints, it actually highlights that the model is focusing on the underlying reasoning process rather than the surface-level output language.
With DeepSeek-R1-Zero, DeepSeek-R1, and 6 distilled models being open-sourced, it will be fascinating to see how these reasoning models influence future trends in LLM research and development. Thank you for reading!

